
Key takeaways:
- MLOps is a concept that enables data scientists and IT teams to collaborate and speed up model development and deployment by monitoring, validating, and managing machine learning models.
- In practice, the ML codes may only take a small part of the entire system, and the other related elements required are large and complex.
- Apache DolphinScheduler is adding a variety of machine learning-related task plugins to help data analysts and data scientists easily use DolphinScheduler.
- Although there are various types of MLOps systems, their core concepts are similar and can be roughly divided into four categories.
- In the future, Apache DolphinScheduler will divide the supported MLOps components into three modules, namely data management, modeling, and deployment.
MLOps, the operation of machine learning models, is a thoroughly studied concept among computer scientists. Think of it as DevOps for machine learning, a concept that enables data scientists and IT teams to collaborate and speed up model development and deployment by monitoring, validating, and managing machine learning models. MLOps expedite the process from experimenting and developing, deploying models to production, and performing quality control for the users.
In this article, I’ll discuss the following topics:
- New functions of MLOps introduced in Apache DolphinScheduler
- Machine learning tasks supported by Apache DolphinScheduler
- The usage of Jupyter components and MLflow components
- The Apache DolphinScheduler and MLOps integration plan
What is MLOps?

MLOps is the DevOps of the machine learning era. Its main function is to connect the model construction team with the business, operation, and maintenance team, and establish a standardized model development, deployment, and operation process so that corporations can grow businesses using machine learning capabilities.
(refs: https://en.wikipedia.org/wiki/MLOps#cite_note-tds1-1)
In practice, the ML codes may only take a small part of the entire system, and the other related elements required are large and complex.

Although there are various types of MLOps systems, their core concepts are s===imilar and can be roughly divided into the following four categories:
- data management
- modeling
- deployment
- monitoring
DolphinScheduler is adding a variety of machine learning-related task plugins to help data analysts and data scientists to use DolphinScheduler.
- Supports scheduling and running ML tasks
- Supports user’s training tasks using various frameworks
- Supports scheduling and running mainstream MLOps
- Provides out-of-the-box mainstream MLOPs projects for users
- Supports orchestrating various modules in building ML platforms
- Applies different projects in different modules according to how the MLOps is matched with the task
ML Tasks Supported by Apache DolphinScheduler
Here is a current list of the supported task plugins:
Jupyter Task Plugin
Jupyter Notebook is a web-based application for interactive computing. It can be applied to the whole process of computing: development, documentation, running code, and displaying results.
Papermill is a tool that can be parameterized and execute Jupyter Notebooks.

MLflow Task Plugin
MLflow is an excellent MLOps open source project for managing the life cycle of machine learning, including experimentation, reproducibility, deployment, and central model registration.
OpenMLDB Task Plugin
OpenMLDB is an excellent open source machine learning database, providing a full-stack FeatureOps solution for production.
OpenMLDB task plugin is used to execute tasks on the OpenMLDB cluster.

Figure 7. OpenMLDB task plugin
Usage of Jupyter Components and MLflow Components
You can configure conda environment variables in common.properties and create a conda environment for executing Jupyter Notebook, as shown here:

Figure 8. Create a conda environment
Call Jupyter task to run Notebook.
1. Prepare a Jupyter Notebook
2. Use DolphinScheduler to create a Jupyter task
3. Run the workflow
The following is a Notebook for training a classification model using the SVM and iris datasets.
Notebook receives the following four parameters:
1. experiment_name: TheExperiment name recorded at MLflow Service Center
2. C: SVM parameter
3. kernel: SVM parameter
4. model_name: The name of the model registered to the MLflow Model Center

Drag Jupyter components to canvas, and create a task, shown below.
The task will run Notebook: /home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm.ipynb, and save the result in the following route:
/home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm/03.ipynb
Set the runtime parameter C to “1.0,” and set the kernel to “linear,” The running conda environment is the kernel: “jupyter_test.”

We can replicate two more identical tasks with different parameters. So we get three Jupyter tasks with different parameters, as follows:

After the creation is complete, we can see our new workflow in the workflow definition (this workflow contains 3 Jupyter tasks). Once the workflow is running, you can click the task instance to check how each task is executed, and view the log of each task.

Usage scenarios
- Data exploration and analysis
- Training models
- Regular online data monitoring
MLflow Component Usage
We can use MLflow task to train the model by following steps:
1. Prepare a dataset
2. Create MLflow training tasks with DolphinScheduler
3. Run the workflow
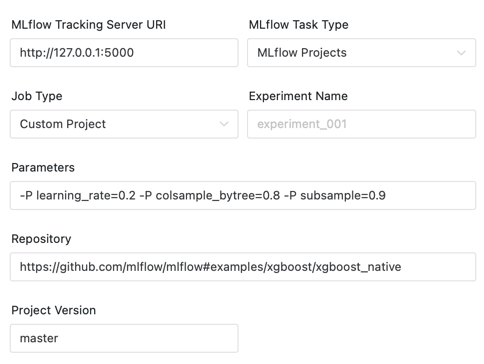
An example of creating a workflow is as follows, including two MLflow tasks:

Task 1: Use SVM to train the iris classification model, and set the following parameters, in which the hyperparameter search space is used for parameter adjustment. If it is not filled in, the hyperparameters will not be searched.

Task 2: Use the AutoML method to train the model. Use flaml as the AutoML tool, and set the search time to 60 seconds, only allowing for using lgbm, xgboost as the estimator.

Deploy tasks with MLflow
1. Select the model version to deploy
2. Use the DolphinScheduler created MLflow to deploy tasks
3. Simple test interface
As mentioned above, we have registered some models in the MLflow Model Center, we can open 127.0.0.1:5000 to see the model versions. Create a task for MLflow Models. Specify that the model is iris_model (production version), and the monitoring port is set to 7000.



Figure 18. Test the Customizable running results
Automatic deployment after training the model, for example:
Using the workflow we created above (Jupyter training model, MLflow deployment model) as a sub-workflow, and connect them to form a new workflow.
Apache DolphinScheduler and MLOps Integration Plan

The above picture is a display diagram of machine learning-related tools and platforms. Apache DolphinScheduler will selectively support some of these tools and platforms that have a wide range of use and high value.
In the future, Apache DolphinScheduler will divide the supported MLOps components into three modules, namely data management, modeling, and deployment. The components involved are mainly DVC (Data Version Control), integrated Kubeflow modeling, and provide Seldon Core, BentoML, and Kubeflow, among other deployment tools to suit the needs of different scenarios.
How to integrate more tools so that Apache DolphinScheduler can better serve users is a topic that we contemplate in the long run. We welcome more partners who are interested in MLOps or open source to participate in the joint career.
About the Author
Name: Zhou Jieguang
Bio: Senior Algorithm Engineer of WhaleOps, Apache DolphinScheduler Committer, 5+ years of working experience in NLP.

GitHub: https://github.com/apache/dolphinscheduler
Official Website: https://dolphinscheduler.apache.org/
Mail List:dev@dolphinscheduler@apache.org
Slack:https://s.apache.org/dolphinscheduler-slack

Daily magazine for entrepreneurs and business owners